
I’m exhausted. I’ve had this bit of code floating around for a long time that aims to replace TCP with a UDP-based protocol. I’ve written about it before, and I arrogantly have made many posts recommending such an approach to the masses, both here on this blog and out in the rest of the internet world.
But man… this is not a job for the faint of heart. I think I’ve finally got it now… I think… but it should be noted that every time I thought I had it working in the past, I eventually proved myself wrong. So I’m writing this post mostly to vent, but also to warn you about the dangers of taking on such a task, and possibly offer you some foresight in the case that you are as crazy as I am.
First a quick little bit of background…

What’s wrong with TCP?
TCP is fairly useful for the general purpose traffic of the internet, but it has its flaws and limitations.
1) Half-Open connections and lack of Keep-Alive standardization.
This was the biggest thing that ticked me off. It was the biggest reason I finally threw my arms up and said “screw this! I’ve had enough!”
TCP has a vulnerability in that the final FIN packet sent to a client can be potentially dropped by routers/networks resulting in a connection that is half-open when the actual intention was to fully close the connection. This and similar approaches have been popular types of Denial of Service attacks as they do not require a lot of bandwidth, yet potentially eat-up valuable handles, sockets, and threads depending on the server implementation, but they can also happen in the real world with increasing frequency thanks to our shoddy wireless carriers.
Operating systems have made attempts to fight back against half-open DDoS attacks by limiting the number of half-open/closed connections that can be present in the operating system at a given time and by introducing maximum lengths of time that connections can remain in a half-open/closed state. Last I checked, personally, however, the time limit on Windows was pretty high (2 days, if I recall).
This condition is further aggravated by the optional nature of TCP keep-alives, which if fully-implemented were intended as a protocol-level (as opposed to application level) solution to detecting dead/zombie connections. But, when TCP was designed, bandwidth was considerably more precious than it is now, and there were concerns that mandadory keep-alive timers for TCP would be too “chatty”. Therefore keep-alives are optional, not generally used, and not guaranteed to be transmitted by routers according to RFC1122. So… even if you enable keep-alives at the TCP layer in an attempt to detect/handle the scenario, you may find that as your traffic travels around the world, some routers are dropping the keep-alive packets… creating potentially ANOTHER rare scenario to test.
Half-Open connections pose a bit of an engineering challenge to coders who write TCP-based servers, particularly, because they can unintentionally appear at random, during times of high-load… and typically on production servers… and can be difficult to notice in Alpha/Beta testing stages. In my experience, I found them to occur in maybe 1 in 40,000 connections on servers handling 2.5million connections/day, but those numbers will vary depending on your traffic conditions and the traffic conditions of every leg of the internet between your server and the client.
As an engineer, it can be difficult to track down problems that occur infrequently and only on live, deployed servers, so it is important to try to simulate this rare-state of connection when writing TCP server code to analyze how your server will react when faced with this situation. If your TCP server uses a static number of worker-threads for example, you may find all of them consumed by zombie connections when you deploy to production, for example. If connections require lots of working memory, then the end-result could appear similar to a memory leak. etc. etc.
Without a 100% viable keep-alive solution TCP leaves it up to the user-layer to determine how half-open/closed connections are handled, so your code has to have a plan/mechanism to detect, time-out, and clean-up resources when this condition occurs… that is… assuming that this is a protocol you invented and not one of the many (bad) open standards that programmers typically use. Of course I’m referring to protocols such as HTTP, which run exclusively over TCP. These protocols are extremely overrated in the opinion of this programmer.
2) Poor Real-Time support
Sometimes you want to transmit data that is inherently optional. No one really wants to intentionally drop data, obviously, but in many real-time protocols, the best alternative to dealing with dropped data, is to simply send more up-to-date data. In the course of TCP transmissions, data can and will get dropped… however you, as a programmer won’t notice it unless you look at the transmissions with wireshark or another sniffer. TCP takes care of the retransmissions for you….
This is usually okay, but when performance is on the line, you might want to have more control over the retry mechanism. For example, you might resend an updated, more timely, version of the data rather than resending data that is now technically “old”. Additionally there are other ways to deal with data loss that may be more efficient and lower-latency… such as the use of forward error correction.
I wanted the ability to build guarantees into the data, while at the same time allowing for optional real-time data channels.
3) Multi-targeting
TCP connections are between one host and one server. Transmitting data to multiple machines at the same time is only possible with UDP under the right circumstances. UDP broadcasts can be considered “unfriendly” however and behave terribly on networks with multiple wireless access points from my observation. It is generally preferable to use multi-cast instead of broadcast.
4) Network switching
TCP Connections are bound to their network interfaces, and are disconnected when switching networks. I have dreamed of implementing a way to maintain a persistent connection even when IP-addresses and network adapters change. I always find it annoying when I drive away from my house and my phone switches over from using wifi to 4G, dropping all my data connections.. or when I’m on a road trip and switching to a new carrier interrupts my Netflix.
Using UDP it should be possible to invent a protocol that maintains smooth transitions from network to network.
5) Multi-homing
Taking the above idea even one step further. I figured it should be possible to build a protocol that takes advantage of multiple-routes to the internet simultaneously whenever available…. so if you have a cable and DSL modem together on the same network, you should be able to use both of them for increased bandwidth. Same would apply to Wifi. You should be able to use 5GHZ and 2.4Ghz simultaneously; you should be able to use Wired and Wireless simultaneously; and you should be able to use multiple wired cards in your server simultaneously.
With TCP it is really only possible to use multiple routes in this way if the routes are to and from the same IP subnet. But if the sources or destinations have multiple-IP targets, packets will get lost. You would have to pass through a VPN tunnel to create a private single-ip destination using multiple routes over multiple networks, which is a network-level configuration thing…
Typically your wireless network card gets a different MAC and IP address from your wired ethernet card… I’ve always found this to be annoying. With a more elaborate protocol, we could potentially enumerate all the IPs and MAC addresses and use them all simultaneously.
6) Peering behind NAT firewalls.
TCP Connections are recognized and recorded by firewalls, and the firewalls generally ensure that traffic is only allowed across the firewall when a computer on the local area network initiates the connection. Therefore it is impossible for two computers behind two different firewalls to talk to each other unless they have the help of a firewall-less server. To many this is a security feature, and, in most cases, this is desirable, however, if you were to want to set-up something like a video conference service, your organization would have to have some pretty serious internet pipes to handle all the bandwidth of all the video calls you were hosting. Programs such as Skype, therefore make use of the fact that UDP is more loosely controlled by firewalls and use tricks to setup private connections between computers… saving them lots of money in most situations. The key thing that makes this work is how the mechanism takes advantage of the fact that the firewall must logically assume that data going out expects a return.. yet since the concept of a “connection” is undefined by UDP, it cannot make any assumptions regarding the success or failure of that connection. Therefore all you really need are two computers behind a firewall to blast a few UDP packets at their respective source ports and you magically have a peer connection that the firewall logistically has no choice but to allow (unless the network admin disables UDP entirely). You’d still need a 3rd party to broker that initial connection, but after that, the data would not have to travel through the broker.
7) Performance over high-ping connections
TCP Sends a group of packets, then waits for a response before sending more. There’s a bit of write-ahead allowed, essentially the “TCP-Window” but the ACKnowledgement mechanism is a bit primitive and could result in stalls due to packet loss. If the TCP window is full, there’s a chunk of time when the acknowledgement is in-transit that the sender must potentially sit around waiting for this acknowledgement. If your data is going to China and back, or is over a satellite link, this time starts to add up quickly, hurting performance. I figured that my UDP-based protocol could use a different kind of acknowledgement system that would allow continued transmission of packets while waiting for past acknowledgements at the same time.
Enter the Untamed Beast, UDP
I had no idea what I was getting into when I took on this mission of building a UDP-based TCP replacement. It turned out to be far more complex than I ever anticipated. I arrogantly went into the problem head-strong with only a loose understanding of what I’d have to do.
I figured it shouldn’t be too hard, right? All I really would have to do would be:
- Send a packet with unique sequence number on the front of it
- log that I had sent it
- Upon reception at the other end, send back another packet acknowledging that I received it
- clear the packet from the transmission log
The Basic Architecture
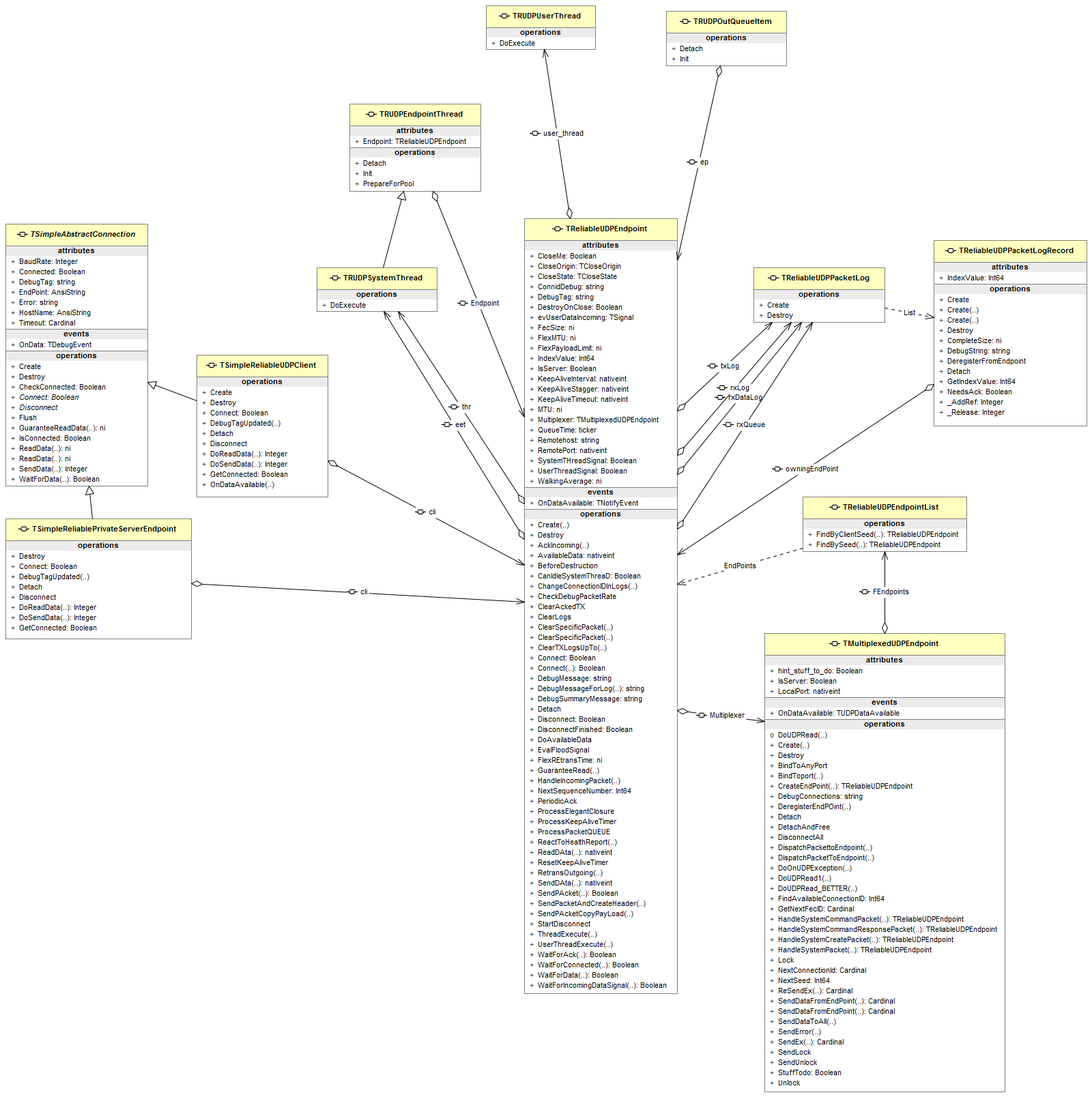
The software architecture was bit tricky but got off to a relatively smooth start. The initial simple setup centered around an Endpoint class and its descendent MultiplexedEndpoint, which would spawn private endpoints for new connections as they arrived. Each endpoint would need a pair of threads: a “system thread” and a “user thread”. In the case that the endpoint was being used as a client, the user-thread would be the calling thread and supplied by the user code, but in the case of a server, the user-thread would be created by the server and then hooked into events that were specific to the server implementation. Aside from some unplanned trickiness with dealing with Connections/Disconnections and elegant thread closures, I got it up and running in a couple of days.
But then came the performance tests.
Initially I had “not good enough but decent” performance in my first tests of the protocol. I found that getting the balance of write-ahead distance and retry times was a bit cumbersome. But eventually I got it blasting close to a gigabit/sec on my LAN.
It wasn’t until I started testing the performance in different directions and on different networks that shit really hit the fan.
To my surprise when computer A talked to computer B on the LAN, things might be peachy, but when B talked back to A, performance would be at a turtle’s pace. We’re talking 1/100th the expected speed!
Furthermore, when I tried it over a distance (across town), it peaked out at a mere 200kb/sec over my 20megabit pipe… and became more unpredictable in the other direction.
Retransmissions became the “norm” and not the exception.
Eventually I put in a system I called the “ringstat” system. It was a set of ratios recorded in a circular buffer that aimed at keeping retries to a minimum by balancing the write-ahead distance.
This worked pretty well for a while and became my standard for about a year, but it wasn’t ever good enough. It didn’t help that I knew that I was doing some things wrong, and I wasn’t testing on a ton of networks, just a few that I had access to. It was a temporary solution.
As I continued to maintain this code for a year, I eventually ported it to work on Android devices. The android devices wouldn’t work with an MTU size >512 and I had relied on being able to send 1400-byte udp messages to keep performance respectable on my windows machines. Upon settling on 512-byte packets, my performance was crawling down at 1mb/sec, even on my LAN.
Eventually I got to a point where I needed this protocol to be used to power my backup system. This was the real-deal now. I needed 1Gb/sec throughput, or close to it, and it needed to work with offsite backups, and real-time restores from offsite. The real-time restores had to complete each zone in 30 seconds or less, otherwise the iSCSI server would time-out. I couldn’t stop now until this was perfected.
If this blog is full of typos and poorly written, it is because I am writing it at the end of a 2-week marathon session of coding, debugging, tweaking, measuring, testing where I literally spent 18-hours a day in front of the computer, hypothesizing, coding, and testing possible solutions. Finally, I think I’ve done it.
Most software engineers have heard that “udp does not guarantee delivery of a message”, but have never really taken the time or initiative to understand what that really means. After all, generally speaking if you send 1 packet of data to a computer, there’s generally a >99% that it will reach its destination. But things looks a lot differently when you’re push around the 244,140 packets you would have to push around every second in order to saturate a 1gb network at 512-bytes each.
It is hard enough to service 24,140 packets (10gb) or even 2,414 packets every second if you don’t approach the software architecture right and ultimately coming up with a datagram size optimization testing algorithm is going to be important.
Packets can get dropped… at any point… during this process. You may think that it will be easy for you to simply retry the packet if it isn’t acked soon enough, but you have to keep in min that it may be acked in <1ms or it may be acked in 1000ms. You never know, and you’ll have to keep these data packets organized efficiently, choose your retry timers wisely based on some kind of measurable data metrics (which may not really directly tell you anything about the conditions of anything).
If you approach this problem without really putting too much thought into it, you’ll fail miserably and if you overthink or overbuild it, it will be slow. Transmitting UDP is a process that can be not unlike firing a shotgun into your Mom’s expensive vase. Receiving UDP is a process not unlike gluing your mom’s expensive vase back together, and controlling UDP is not unlike predicting and controlling the weather.
Packets can be lost at any level. When you send a UDP packet, it goes from your application, to:
- a software buffer at the OS level
- the network card drivers
- the network card/chip
- over the ethernet, or wireless
- to your internet gateway (network receiver->driver->OS->firewall/routing application code->OS->driver->network transmitter->wire/wireless)
- to your dsl/cable modem or other (network receiver->driver->OS->firewall/routing application code->OS->driver->network transmitter->wire/wireless)
- through the first hop to its destination of the internet which may include (network receiver->driver->OS->firewall/routing application code->OS->driver->network transmitter->wire/wireless)
- etc. etc. etc. potentially thousands of opportunities to be dropped
- If you’re lucky it doesn’t meet any congestion, hiccups, buffer overruns, collisions, interference, at any of those potentially thousands of junction points along the way and it lands at the door of your application and you get a message “there’s a UDP packet available”
I have a packet, lets look at it!
Well, you better not just look at that packet directly, you had better, in fact, set up a queue on a different thread. Get the packet out of the UDP thread as fast as possible so that there’s room in the buffer for more UDP packets, otherwise those packets will travel across the world only to be turned down at your doorstep by the OS. The OS will start dropping packets if you don’t empty them out as quickly as possible. You’ll need an efficient queue for this. Don’t think you can get away with just adding them to a generic list or collection, it turned out that a major performance problem of mine was that I wasn’t running fast enough lists. Figuring that my lists would typically average around 32-items per list, I thought I could get away with a simple list, but in actuality, an AVL-Tree begins to outperform a linear list after around 7-items, and a linked list not requiring any sort of walking probably outperforms that linear array after just 3 items are added to it. I was shocked to learn that I needed super-efficient lists to handle this data, despite the fact that the lists were short.
Use a linked-list for your queues, don’t write to logs, be conscious of the number of heap operations you are performing, don’t concatenate any strings, don’t do anything in this thread but move the packet to a queue.
So I have a packet, from my queue, what do I do with it?
Well, you probably want to acknowledge it very quickly, but maybe not. In fact, if you send too many ACKs too quickly, you run the risk of adding congestion to your incoming traffic and/or the ACKs just getting lost anyway. Determining an appropriate rate of acknowledgement is important. I suppose what I settled on was a system whereby which I might voluntarily defer ACKs if the UDP thread had pending data incoming. Get the data first, ACK in-between. TCP generally ACKs every 2nd packet to reduce congestion, so clearly the designers of TCP understood that ACK congestion is a problem. ACKing every second packet, however is obviously a pretty primitive approach… I’m not even sure what my system is doing with the ACK rate at the moment, but I tried a number of different approaches and rates and congestion controls…. more on that later though.
Increasing message sizes
It may be completely unfeasible, depending on your performance targets and target systems, to service 240,000 packets in the user-layer given all the OS thread scheduling contentions your application may be up against, so therefore you may be tempted, after failing to achieve your performance goals, to attempt to negotiate a larger MTU. I tried this, I will say, and it didnt’ work out for me. Larger MTUs often result in a higher likely hood of packet loss in many situations. Furthermore, you’d still have to come up with a way to alter your TX logs and split the MTUs while still taking into account that the original, larger MTU you sent may be out there bouncing around somewhere. All this logic takes up additional CPU time and adds latency to your operation and it is highly unlikely that you’ll get good results with frames larger than 1400ish bytes, and officially you’re only guaranteed that 512 will work at all. After getting unpredictable gains in the attempting to split/combine MTUs. I opted for a different approach.
Update: Ultimately, after exchanging data between USA and China on a terrible network, I implemented a larger MTU negotiation system backed by a 512-byte manual splitting algorithm. I found that datagrams larger than 512-bytes would work, most of the time, but every once in a while would yield complete failure forcing me to reset the MTU negotiation back to a “safe” level. This posed an additional challenge because those datagrams that were already sent had to be repackaged (while preserving their sequence numbers) and resent in 512-byte chunks.
Forward Error Correction … to the rescue?
After doing some reading, someone on the internet somewhere suggested implementing an error correcting scheme. I dove head-first into an implementation, confident that if I just did this, my protocol would be invincible! Well… whereas it did turn out to be a valuable addition that I kept (Update: No it didn’t… I went back to a simpler approach eventually) , it didn’t work nearly as well as I hoped it would. I’ll explain:
Forward Error Correction is a means by which you send along error correcting information in the stream that can correct missing data. There are multiple methods of doing this, but I chose a simple XOR principal similar to what I use in my RAID system. Lets assume you have 4-bits of data and they are 1101. Since there are 3, 1’s in that string of numbers, you have “odd parity”. So your error bit is 1. If you had an even number of 1’s, your error bit would be 0… this is called “even parity”. So 1100 would have an error bit of 0. Now lets assume you lose one of the original bits. By simply XORing the original bits with the parity bit, you will now know the original missing bit. So In the case of 11×1 we had a partity bit of 1, which when XORed with the remaining bits gives us 0. I won’t go any further than this in describing it, because you can look it up on Wikipedia or something.
Anyway… I setup an error correcting system where I would send 8 packets followed by a 9th parity packet. If any of the first 8 packets were dropped, there might be a chance than the 9th would make it, right?
Well… not really, as it would turn out. In fact, it was pretty likely that if any of the 8 original packets were dropped, the 9th would almost invariably get dropped, followed by a hundred packets following it.
The characteristics of UDP transmission, unfortunately are, similar to if you poured a bucket of water into a funnel, which then poured into another funnel that might be smaller or bigger, followed by another funnel… etc. You don’t know how big the funnels are… but at some point they spill over. UDP can sustain short bursts of data at times, but the buffers in each chain along its network path are all like their own little funnels, and if they spill they make a big mess. Error correcting data didn’t really help with that at all in the direct sense… but I think I found a way to use it in a slightly different way than I originally planned.
What I ended up doing was increased my message size up to around 20,000 bytes, and integrated high-performance tick-counting from the OS to space out the packets. How much spacing to use was highly variable, so there were no good settings to use that would come close to working everywhere. But to solve this issue I modified my ACK message.
Since the sender would send data in 512 byte packets, with a parity packet every 8 packets (I tried 3,4,15,etc.. all the same), I didn’t really need all the packets in order to get a message successfully.
So I modified my ACK message format to include a little “Health Report”. The health report would be delivered upon the successful completion of a 20,000 byte message and it would basically say “Yeah, I got your message, and this is how healthy it was”.
Now if the message was “too unhealthy”, meaning that the other end lost more than a desirable number of packets during as detected by the reconstruction process, then I’d bump down the speed dramatically (cut in half).
But keeping in mind that a message that is fully intact is not really desirable, the message could therefore be considered “too healthy”. 0% packet loss is undesireable, we want to lose a reasonable amount of packets in every message and walk a nice tightrope of performance. If the message is “too healthy”, the system figures that it can bump up the speed of the transmission a bit.
The ultimate goal is to get the messages in from a single transmission, with a few packets lost, but not so many packets lost that reconstruction fails.
Recognizing the weaknesses of TCP and its unfortunate popularity for transmitting HTTP/Web traffic, smart companies have sought to seek out a replacement. For example, Google experimented with a protocol called QUIC (which came up again in the Google IO 2016), which transmits HTTP over UDP. There’s also an open protocol called TSCP. None of those protocols have seen wide adoption however.
I hope however, that having my own UDP-based protocol makes my own systems more resilient, easier to maintain, and less error prone than my TCP systems.
Ulysses Green: I’m not gonna lie, this article is a wild ride. I’ve been working with protocols for years and I gotta say, the author’s enthusiasm is infectious. But let me ask you, have they really cracked the code on UDP? I mean, we all know TCP has its flaws, but can UDP really replace it? I’m not so sure.
@dan: shut up