

Download BigBrain2020.
If you are using the standard Delphi Memory manager in your Delphi applications, you’re probably missing out.
One of the things, I really like about Delphi is that it ahs always offered an easy way to replace the memory manager with your own, or one that you get from a 3rd party. Being a nuts-and-bolts kind of programmer, coming up with a better memory manager for Delphi naturally became an intense personal obsession.
I have also always been particularly fascinated by the idea that a computer could have multiple CPUs and, therefore, do more than one thing at the same time. I built Big Brain as a personal challenge… to see if I could make Memory Allocations run faster on systems with multiple cores and CPUs.
The first version was released circa 2000, and was eventually adopted by hundreds of companies and organizations. I stopped “selling” it in 2007, giving it away for free on a boring, white web page with just a couple of links.
20 years later, I am still just as obsessed with nuts and bolts and multi-processing, and I test out my designs on an AMD 2990WX chip, which has 32 cores, capable of handling 64-threads in addition to various 16, 8, 6, 4, and 2-Core Intel and AMD chips.
So why haven’t I updated the Big Brain Memory Manager since 2013?
1) It works pretty great as it is.
2) The space had become crowded with what I assumed to be solid solutions.
3) Operating Systems and Micro-architectures have improved memory handling, making it less essential (although still very valuable)
It used to be that, on multi-CPU systems, contention for mutexes/critical sections/other kinds of locks incurred a HEAVY penalty. These days there is still a penalty, but less so. Back in the day, your apps would become virtually unusable if they fought over locks. It was so bad that we found that an app running just a few threads parsing strings would become so slow that it appeared to have locked-up entirely. The performance would tank exponentially in relation to the number of threads running in your app. I’m not an engineer for AMD or Intel or Microsoft, but it is apparent to me that they’ve made lots of changes to help with this both in the Micro-architecture and Operating System over the years.
Big Brain is needed “less” these days, but as the numbers I am about to show you will demonstrate, it is very much still beneficial. I use it every day in literally every app I build.
The bottom line is… BigBrain, despite not having been updated since 2013 can still scale better than the stock memory manager.
So why update it in 2020?

The biggest thing that drove me to update Big Brain was that, in order to promote block reuse, memory blocks were allocated in powers of TWO, exclusively. On average, that meant that you actually consumed 2X the RAM you actually needed, a huge waste, as the average waste, given random allocations, would always sit at 50% of a power of 2… (math!)
So now… it’s 2020… I’ve got a LOT more RAM now (192GB on one machine) and I died a little bit inside when I saw I was wasting 55GB of RAM in an app that required 110GB! So I really wanted to get rid of the power-of-two requirement for block sizes and replace it with a variable, possibly Fibonacci system … hopefully without hurting performance (as choosing the right bucket now becomes more expensive). By using a potentially variable “bucket system”, memory waste is WAY down, I’ve reclaimed about 40GB back from that 110GB that I was allocating earlier!
Another problem was that it was slower than the stock memory manager on single-thread tests in many cases… I decided to take another stab at cutting a few more instructions out of the overhead. In that process I found a just a couple of redundant subtraction operations that, when removed, brought the speed close to par in the areas where it fell down. When you’re dealing with code that is used by, basically, everything, every single instruction consumes precious, precious time! Doing the most you can with the fewest possible instructions can be quite the challenge!
I posted my first performance tests to a Facebook group a little prematurely, but the numbers looked absolutely stellar. But upon further testing, I discovered that the nature of the test had a LOT to do with how a particular memory manager performed. In particular, I discovered that, although Big Brain performed quite consistently regardless of the size of memory blocks being allocated, some of the other managers offered widely varying performance , by design, depending on the memory block sizes being allocated. It then became apparent to me that I’d be telling an incomplete story to the world, and to myself, if I didn’t examine variable block-sizes independently.
But hey, I’ve always wanted an excuse to build a 3D Surface chart in Excel, so this was a golden opportunity!
So, for starters, here’s the Standard Memory Manager: If you only allocate small blocks and use a few threads you’d probably be oblivious to the fact that it doesn’t scale much at all and performs poorly on larger block sizes.
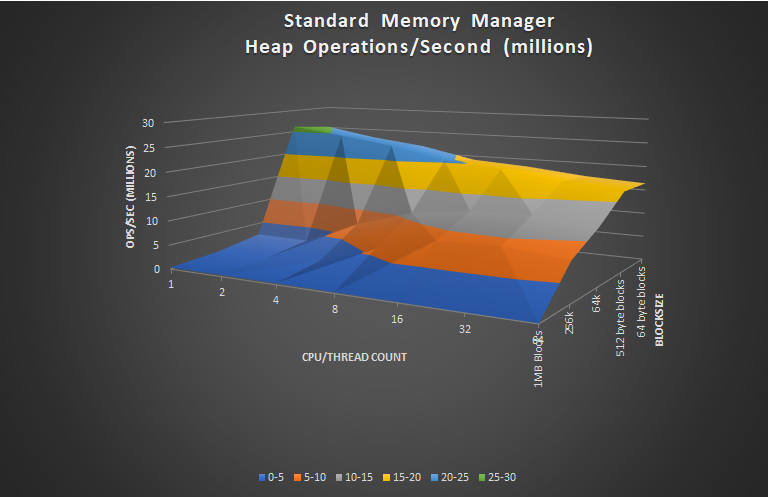
This test was conducted on a AMD Threadripper 2990WX, a 32-core/64-thread chip
The test itself is very synthetic (and brutal). It aims to stress the Memory Manager by simply bashing it with repeated GetMem and FreeMem calls of random sizes. Each thread runs for 8 seconds, and at the end, I simply sum up the number of iterations that each thread was able to complete. As you can see the Standard MM did pretty well with small blocks. In fact, it was quite speedy at dealing with tiny blocks, however, once the blocks were anything-but tiny, performance slowed to a crawl.
Also note that this memory manager performed best with one thread, then performance declined as thread counts increased.
So here’s the same test, performed with Big Brain 2020. Note the scale of this chart reaches 60M ops/sec (double the previous chart).
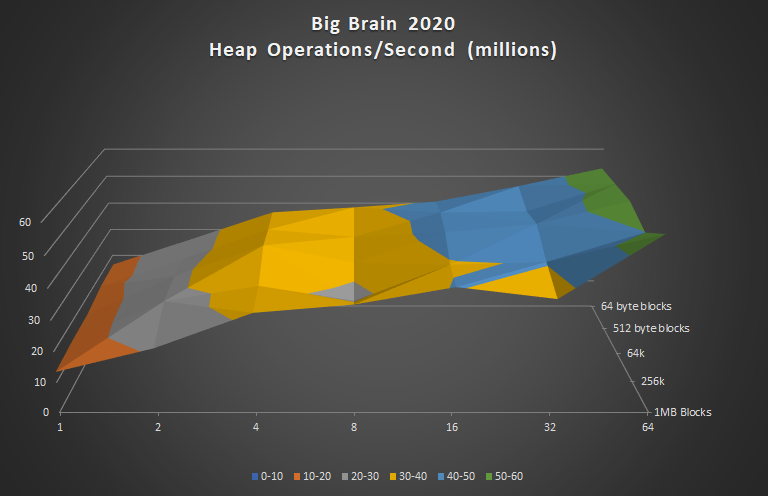
Although Big Brain is not as quite as fast out of the gate in the single-threaded tests for small blocks, it approaches 60M heap operations once the thread-count maxes out, which is double what the standard memory manager was able to accomplish in its best test (which was tiny blocks in 1 thread). Also observe that it delivers more consistent performance among all block sizes, in fact it outperformed the standard memory manager by 15x with 256K blocks!
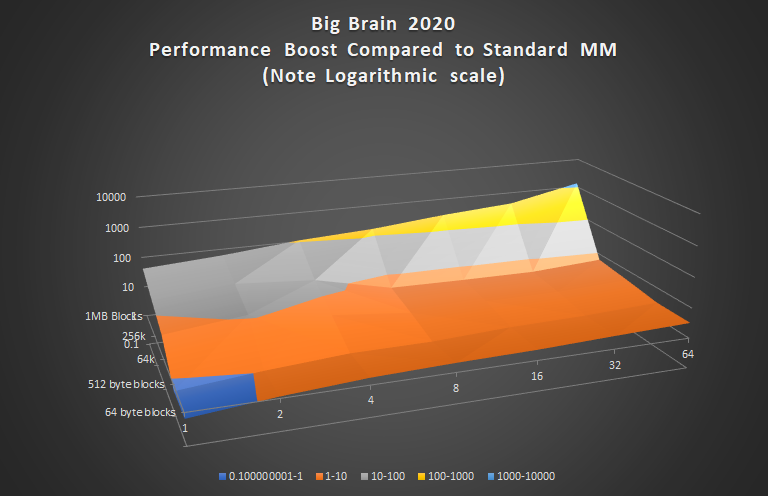
The above chart is another way of looking at the data, which shows the performance in relation to the Standard MM test. The blue areas are where performance was poorer than the Standard MM, all other colors represent a performance boost, sometimes more than 1000x.
The conclusion I draw from this data is that: if your app allocates anything other than tiny, tiny, blocks of memory, you might be better off with Big Brain. You’ll also notice that Big Brain’s performance increases as you throw more CPUs at it whereas the standard memory manager decreases in performance. It also performs fairly uniformly across all block sizes. This will be important when I post results of some real-world operations involving string parsing.
Big Brain vs. FastMM5
So now, here’s another very popular, widely used memory manager, FastMM,
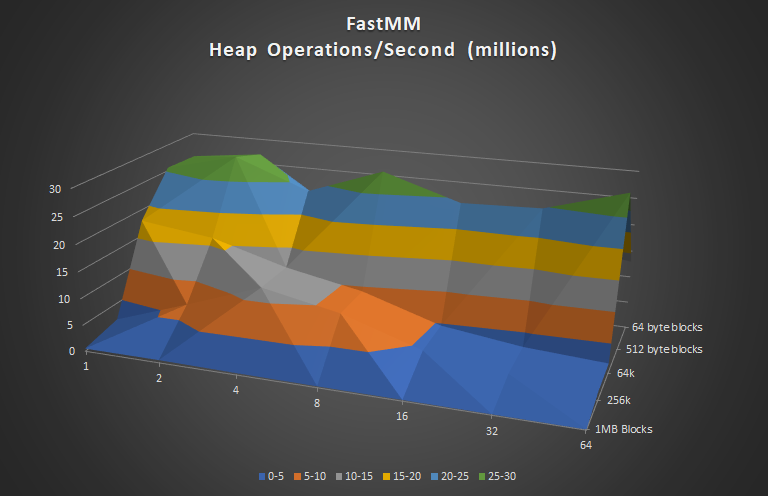
FastMM5 never achieves more than 30M Heap Operations/sec in any test of any size, but it delivers some pretty good numbers for small blocks though and does better than the standard memory manager for slightly larger blocks. Similar to the Standard MM, FastMM5 doesn’t accelerate as thread-counts increase, however, performance doesn’t decline nearly as quickly as the Standard MM.
So now let’s compare Big Brain to Fast MM.
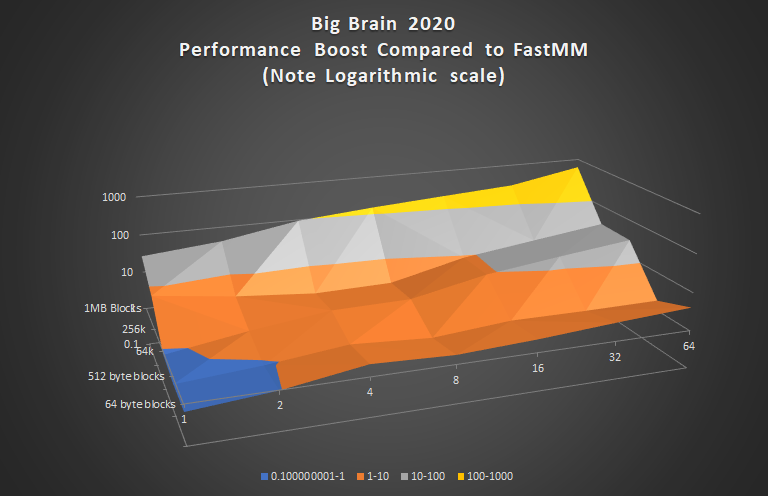
Again, the blue areas are where Big Brain would give you a performance penalty, all others are a performance boost which tops out at nearly 1000x this time.
Big Brain vs. TC Malloc
And now for the stiffest competition I was able to find: TC Malloc. TC Malloc is a DLL you can plug into your Delphi app that is written in C++. Distributing a 3rd party DLL may or may not be a disincentive to you vs. having code written in pure Pascal, however, C++’s O3-Level Optimization is the world-standard of fast. TC Malloc (the TC stands for “Thread Caching”) has an internal design based much on the same philosophy of Big Brain, where each thread gets it’s own heap manager, but can trade blocks with other threads and with the OS. Let’s see how it does.
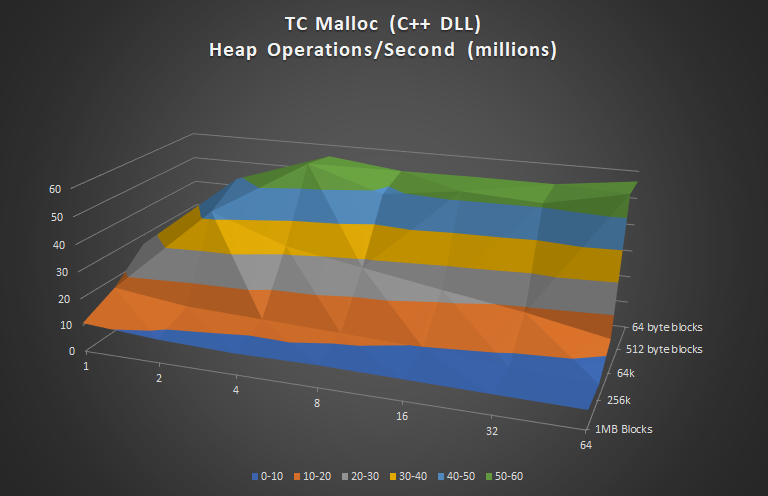
Certainly at first glance this looks to be a pretty zippy memory manager. Hats off to the authors! Seeing this chart for the first time, I’ll admit, made me a little nervous! Did I really make the fastest, best scaling memory manager out there? Let’s look at the comparison graph.
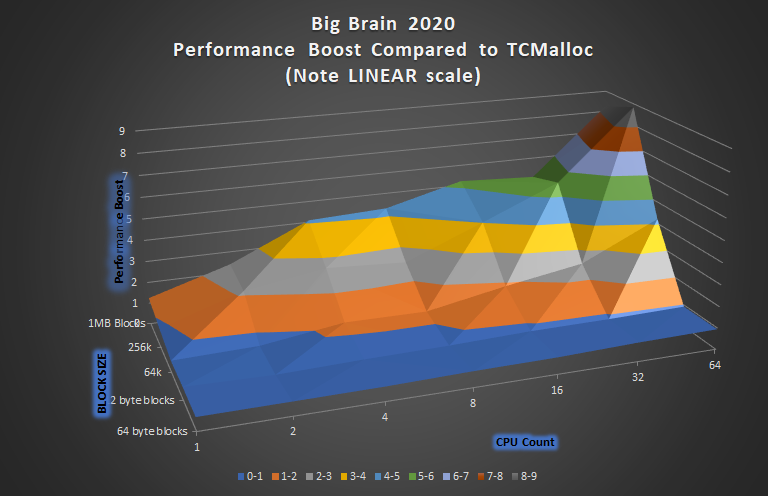
Note that I’ve removed the logarithmic scaling which was necessary to effectively show performance comparisons to the other managers (where the boost was sometimes 1000x). Also note that I have been reversing the block size axis orders on these comparison charts, otherwise we’d be looking at the mountain as-if inside-out.
It looks like Big Brain is winning some, and losing some depending on the block sizes. Again, blue is a performance penalty, all other colors are a performance boost topping out at around 9x. Choosing between the two memory managers at this point will likely depend on your specific app’s needs, threads counts, and block sizes.
As I finish writing this, I am feeling inspired to try and chip away at some of the blue areas of this chart. It may require taking a completely different approach given small block sizes… a simpler one maybe. My brain is churning with ideas. Rest assured, I will not stop working to make sure that Big Brain is the fastest and most scalable memory manager on the planet.
Big Brain 2020 vs Big Brain 2013
Finally, here is how Big Brain 2020 compares to 2013 in terms of speed. Note that my primary goal was to match the speed of 2013 while reducing memory waste, not necessarily out-perform it by leaps and bounds.
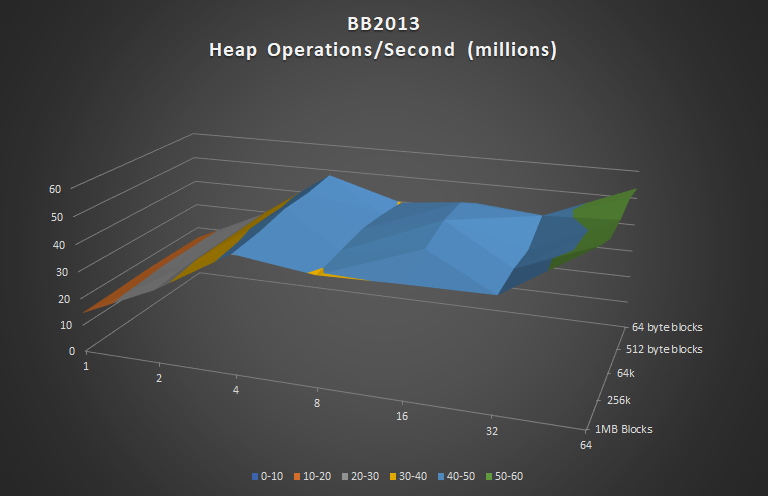
An interesting observation just how uniformly BB2013 serves up blocks of various sizes. The way it is designed is such that block size essentially has no impact on speed. This isn’t quite the case for BB2020, as it will take a slightly longer amount of time to find a bucket for a block of a larger size, due to the increased complexity of the block indexing method.
I think it is worth it though, considering the amount of reduction in wasted RAM.
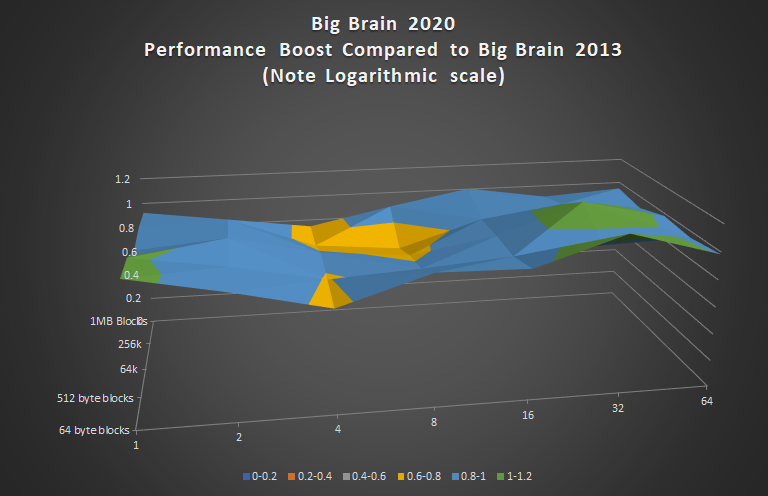
Although the performance of BB2020 isn’t quite as consistent as BB2013, BB2020 holds its own and the pros far outweigh the cons in my opinion. I intend to use B2020 exclusively from here on out.
But the bottom line is, use the memory manager that is best for your particular application, and I’ll be distributing both versions of Big Brain the ZIPs that I publish.
You can download BigBrain2020 for Delphi at https://digitaltundra.com
hello,
please can you put it in github?
I want enhance your code for faster results in single thread app
Can the memory manager be encapsulated in a package in Delphi 10.4.1? I have problems to achieve it.
Also, would be possible to made it platform independent? there is some kind of unit that requires the graphics unit. It would be nice to not depend the package from VCL or FMX
I use FastMM5, in a process with 100 Threads it takes 1 hour to process. With BigBrain it takes 15 minutes, it’s insane, and it could be better. FastMM5 uses 100% of the CPU, BigBrain 80% and I have 2 CPUs (Intel Xeon E5-2673 v4 on Windows 10 for Workstation) with 20 cores each (Total 80 Threads), both use only 1 CPU. FastMM5 uses 50% of the total and BigBrain reaches a maximum of 40% of the total. What define to enable the use of the 2 CPUs? Only in the paid version? How to proceed to acquire the commercial license?
*My application is not commercial, only for my private use.
Before move to FastMM5 i decided to review other memory managers. For testing I use my version pf “Fastcode memory manager challenge” project.
Unfortunately BigBrain just did not perform. I attached a simple test Delphi console application (for version 10.4) below which executes in 2 secs for Default Delphi memory managers, but never completes with BigBrain MM?
Best Regards,
Pavel
///////////////
program MMTest;
{$APPTYPE CONSOLE}
{$R *.res}
uses
BigBrainUltra,
BrainWashUltra,
System.SysUtils,
Winapi.Windows;
var
i, n, vOffset: integer;
vStartTicks: Cardinal;
vStrings: array of string;
begin
try
vStartTicks := GetTickCount;
for n := 1 to 10 do
begin
{ Allocate a lot of strings }
SetLength(vStrings, 3000000);
for i := Low(vStrings) to High(vStrings) do begin
{ Grab a 20K block }
SetLength(vStrings[i], 20000);
{ Touch memory }
vOffset := 1;
while vOffset <= 20000 do
begin
vStrings[i][vOffset] := #1;
Inc(vOffset, 4096);
end;
{ Reduce the size to 1 byte }
SetLength(vStrings[i], 1);
end;
end;
Writeln(GetTickCount – vStartTicks);
except
on E: Exception do
Writeln(E.ClassName, ': ', E.Message);
end;
end.
First off, what you are doing here is really cool. however, I tried it with a test that allocates lots of objects and assignes some values such as strings and numbers to them to compare with the standard memory manager. The standard is about twice as fast and takes up less memory. Delphi 10.4 with a single threaded test.
BigBrain Memory Manager
Allocates: 31.8370004184544
FreeTime: 1.22800015378743
Peak Mem: 536,440k
Default Delphi Memory Manager
Allocates: 15.9439998446032
FreeTime: 0.659999437630177
Peak Mem: 392,096K
couple of things:
1. If your app is truly just a single thread, The standard memory manager runs in a mode that avoids all locks and it considerably faster. However if your app starts up a second thread, the standard memory manager becomes slower. Since big-brain starts up a second thread for cleanup, it is going to automatically kick delphi into multi-threaded mode.
2. Big Brain is not designed for single threaded apps, but instead is designed to make your multithreaded apps run better. The memory manager will absolutely cripple your multi-threaded apps and is a huge limitation.
thanks, it looks very promising.
But I’m trying to compile it on OSX64 and the {$I BBOSX.inc} is missing in the zip package.
Any way to get this file ?
senso
BigBrain is not going to compile on OSX. in fact, my testing in the past showed that Linux/Unix based kernels do not need it (memory management is different).
Compile it out with an {$IFDEF} when on non-windows platforms.
I am having an issue when I use this on a server. It throws an exception “insufficient quota to complete the requested service”. This happens on a call to TDirectory.CreateDirectory. Searching the web it looks like it could be related to the PageFile size or an AV program. I don’t get this error with FastMM4 or ScaleMM2. Thanks.
Hmmm… I use BigBrain on literally everything. The biggest and most obvious issue I encounter is when people don’t use BigBrainUltra as the FIRST file in the project’s uses clause and instead put it second or later.
delphi 10.2
error while build first time
[dcc32 Error] BigBrainUltra.pas(2): E2026 Constant expression expected
{$IF CompilerVersions < 33}
{$IFNDEF BB2013}
{$ENDIF}
{$DEFINE BB2020}
{$ENDIF}
{$MESSAGE '*********************************************************************'}
{$MESSAGE 'BigBrain————————————————————-'}
{$MESSAGE '*********************************************************************'}
{$DEFINE DISABLE_INTERFACE}
{$DEFINE DISABLE_IMPLEMENTATION}
{$DEFINE DISABLE_INITIALIZATION}
{$DEFINE DISABLE_FINALIZATION}
Thank you for this piece, works nicely here. The difference with FastMM5 is actually evident
First, let me say .. I was very excited to try this out. After some initial tests, I was seeing some positive results. Thought I would provide some feedback as to what I was seeing …
I found that if I try to use TZipFile, and extract files 1 by 1 via zipFile.Extract(zipFile.FileName[i], ‘somepath’, false);
That it will cause an error “insufficient quota to complete the requested service”
This is my extract loop if you want to test. I am using Delphi 10 Seattle, with the compiler fix applied.
zipFile := TZipFile.Create;
zipFile.Open(‘Avalid.zip’, zmRead);
For i := 0 to zipFile.FileCount – 1 do Begin
zipFile.Extract(zipFile.FileName[i], ‘C:\Temp’, False);
// the first file in the ZIP will extract, the second file throw the error.
// when using scaleMM I do not have this issue
End;
Result := zipFile.FileCount;